正则表达式
多个字符
| 匹配区间 | 正则表达式 | 记忆方式 |
|---|---|---|
| 除了换行符之外的任何字符 | . | 句号,除了句子结束符 |
| 单个数字, [0-9] | \d | digit |
| 除了[0-9] | \D | not digit |
| 包括下划线在内的单个字符,[A-Za-z0-9_] | \w | word |
| 非单字字符 | \W | not word |
| 匹配空白字符,包括空格、制表符、换页符和换行符 | \s | space |
| 匹配非空白字符 | \S | not space |
161563
匹配次数
0 | 1
元字符?代表了匹配一个字符或0个字符,匹配color和colour,/colou?r/
>= 0
元字符*用来表示匹配0个字符或无数个字符
>= 1
元字符+适用于要匹配同个字符出现1次或多次的情况。
特定次数
- {x}: x次
- {min, max}: 介于min次到max次之间
- {min, }: 至少min次
- {0, max}: 至多max次
| 匹配规则 | 元字符 | 联想方式 |
|---|---|---|
| 0次或1次 | ? | 且问,此事有还无 |
| 0次或无数次 | * | 宇宙洪荒,辰宿列张:宇宙伊始,从无到有,最后星宿布满星空 |
| 1次或无数次 | + | 一加, +1 |
| 特定次数 | {x}, {min, max} | 可以想象成一个数轴,从一个点,到一个射线再到线段。min和max分别表示了左闭右闭区间的左界和右界 |
边界
The cat scattered his food all over the room.
匹配cat,而不匹配scatte 用\b
/\bcat\b/
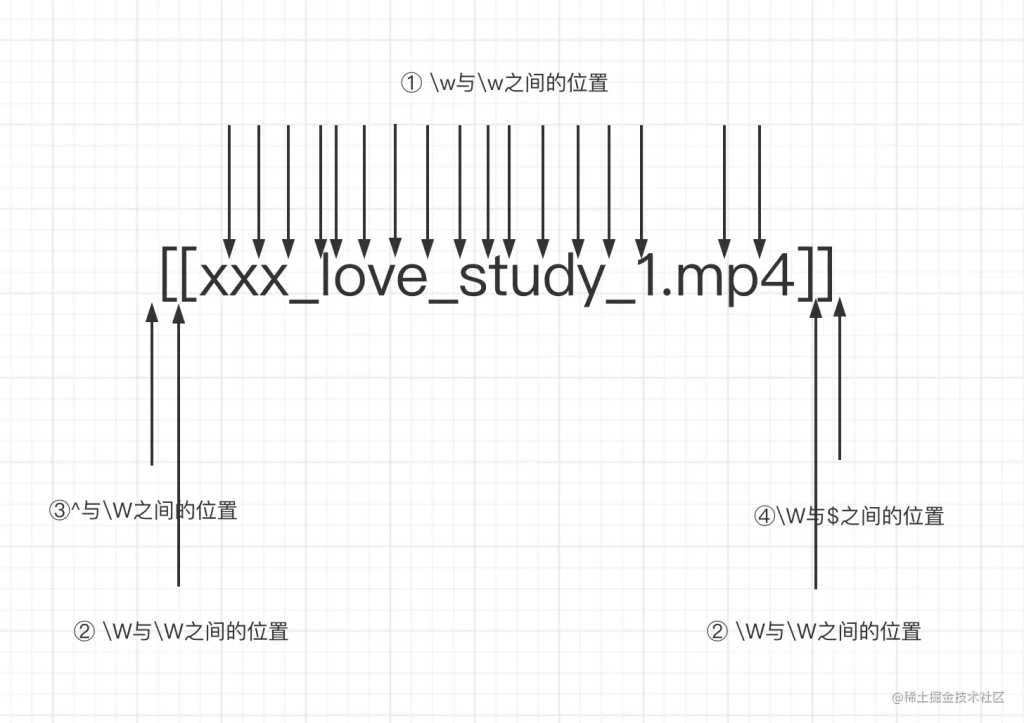
xxx_love_study_1.mp4,想要把他变成❤️xxx_love_study_1❤️.❤️mp4❤️
'xxx_love_study_1.mp4'.replace(/\b/g, '❤️')
'[[xxx_love_study_1.mp4]]'.replace(/\B/g, '❤️') 会变成
❤️[❤️[x❤️x❤️x❤️_❤️l❤️o❤️v❤️e❤️_❤️s❤️t❤️u❤️d❤️y❤️_❤️1.m❤️p❤️4]❤️]❤️
如匹配I am scq000.这个句子:
I am scq000.
I am scq000.
I am scq000.
/^I am scq000\.$/m
| 边界和标志 | 正则表达式 | 记忆方式 |
|---|---|---|
| 单词边界 | \b | boundary |
| 非单词边界 | \B | not boundary |
| 字符串开头 | ^ | 小头尖尖那么大个 |
| 字符串结尾 | $ | 终结者,美国科幻电影,美元符$ |
| 多行模式 | m标志 | multiple of lines |
| 忽略大小写 | i标志 | ignore case, case-insensitive |
| 全局模式 | g标志 | global |
总结
| single char | quantifiers(数量) | position(位置) |
|---|---|---|
| \d 匹配数字 | * 0个或者更多 | ^一行的开头 |
| \w 匹配word(数字、字母) | + 1个或更多,至少1个 | $一行的结尾 |
| \W 匹配非word(数字、字母) | ? 0个或1个,一个Optional | \b 单词"结界"(word bounds) |
| \s 匹配white space(包括空格、tab等) | {min,max}出现次数在一个范围内 | |
| \S 匹配非white space(包括空格、tab等) | {n}匹配出现n次的 | |
| . 匹配任何,任何的字符 |
$1,$2...是表示的小括号里的内容
$1是第一个小括号里的 ,$2是第2个小括号里的
比如 /hell([\w]+?)world([\d]+)/
匹配 helloworld123
$1= 括号里的 o
$2= 第2个括号里的 123
阅读剩余
版权声明:
作者:chun
链接:https://chun53.top/1650.html
文章版权归作者所有,未经允许请勿转载。
THE END